
Nesse post você via entender como funcionam três algoritmos importantes: Principal Analysis (PCA), Singular Value Decomposition (SVD) e Latent Semantic Analysis (LSA). Porém, antes disso é preciso relembrar alguns conceitos importatantes apresentados anteriormente na nossa série de posts sobre PLN.
Mãos no código
# primeiro você precisa importar as bibliotecas nltk, numpy e matplotlib (lembre-se de instalar elas em seu ambiente)
import nltk
import numpy as np
import matplotlib.pyplot as plt
# você também precisa importar um stemmer e um lematizador que já existe dentro do NLTK
import from nltk.stem import WordNetLemmatizer
# importe também o algoritmo de SVD presente no SKLearn (também é preciso instalar esse pacote)
from sklearn.decomposition import Truncated SVD
#crie uma nova instância do objeto wordnetLemmatizer.
wordnet_lemmatizer = WordnetLemmatizer()
# faça a leitura do dataset (lembre-se de colocá-lo em uma pasta que o python consiga encontrá-lo)
titles = [ line.rstrip() for line in open ('all_book_titles.txt')]
# aqui começamos a definir uma função de tokenização
def my_tokenizer(s):
# reduz as palavras para lowercase (letras minusculas)
s = s.lower()
# Faz a tokenização das palavras
tokens = nltk.tokenize.word_tokenize(s)
into words (tokens)
# remove palavras pequenas pois provavelmente não serão úteis
tokens = [t for t in tokens if len(t) > 2 ]
# remove as stopwords (palavras que não tem muito significado [The, where, was, etc]
tokens = [t for t in tokens if t not in stopwords]
# remove qualquer dígito (número)
tokens = t for t in tokens if not any (c.isdigit() for c in t)]
return tokens
# Agora devemos criar um mapa word-to-index. Assim podemos criar os vetores de frequência mais tarde
# Vamos salvar também as versões tokenizadas (para não precisar tokenizar denovo)
word_index_map = {}
current_index = 0
all_tokens = []
all_titles = []
index_word_map = []
error_count = 0
for title in titles:
try:
title = title.encode('ascii', 'ignore').decode('utf-8') # Isso vai jogar uma exceção se tiverem caracteres errados
all_titles.append(title)
tokens = my_tokenizer(title)
all_tokens.append(tokens)
for token in tokens:
if token not in word_index_map:
word_index_map[token] = current_index
current_index += 1
index_word_map.append(token)
except Exception as e:
print(e)
print(title)
error_count += 1
## apenas exibe um exemplo
dict_items = word_index_map.items()
print("Exemplo do que cada vetor contém:n")
print("Word_index_map: ", list(dict_items)[:5])
print("title: ",all_titles[:1])
print("tokens: ", all_tokens[:1])
print("index_map: ", index_word_map[:1])
## mostra um relatório de erros
print("Number of errors parsing file:", error_count, "number of lines in file:", len(titles))
if error_count == len(titles):
print("There is no data to do anything with! Quitting...")
exit()
## saída
Exemplo do que cada vetor contém:
Word_index_map: [('philosophy', 0), ('sex', 1), ('love', 2), ('reader', 3), ('reading', 4)]
title: ['Philosophy of Sex and Love A Reader']
tokens: [['philosophy', 'sex', 'love', 'reader']]
index_map: ['philosophy']
Number of errors parsing file: 0 number of lines in file: 2373
# transforma tokens para vetores
def tokens_to_vector(tokens):
x = np.zeros(len(word_index_map))
for t in tokens:
i = word_index_map[t]
x[i] = 1
return x
Note que neste exemplo não temos nenhum rótulo. O PCA e o SVD são algoritmos não supervisionados, ou seja, eles aprendem a partir da estrutura dos dados e não para realizar predições.
a seguir nós criamos a matriz de dados
N = len(all_tokens)
D = len(word_index_map)
X = np.zeros((D, N)) # Cria uma matriz gigante de zeros baseado na quantidade de tokens e documentos
i = 0
#chama a função de transformação de vetores para cada linha do array
for tokens in all_tokens:
X[:,i] = tokens_to_vector(tokens)
i += 1
Note como nós divergimos da nossa matriz normal N x D e ao invés disso criamos D x N.
Finalmente, vamos usar o SVD para criar um scatterplot dos dados, ou seja reduzi-los a 2 dimensões e anotar cada ponto com sua palavra correspondente.
svd = TruncatedSVD()
Z = svd.fit_transform(X)
plt.scatter(Z[:,0], Z[:,1])
for i in range(D):
plt.annotate(s=index_word_map[i], xy=(Z[i,0], Z[i,1]))
plt.show()
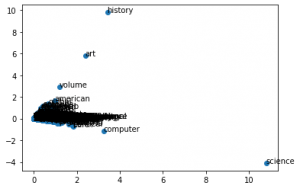
No Gráfico acima podemos perceber que ciências e história ficaram bastante separados, isso pode significar que essas palavras correlatas ficam agrupadas no mesmo vetor (ou seja, próximas).
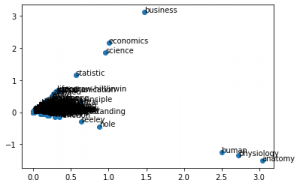
No gráfico acima fica masis evidente ainda que ciências (statistic, science, economics, business) estão mais próximos e destacados. Assim como human, physiology, anatomy (todas relacionadas entre sí).
Se você já usou o LSA, PCA ou SVD em outros conjuntos de dados, deixe seu comentário aqui e compartilhe com nossa comunidade.


