
Seja bem vindo a programação Web, nesse artigo de introdução você vai aprender alguns os conceitos básicos da programação para web e algumas técnicas desenvolvidas para facilitar a sua vida no desenvolvimento web. Algumas coisas que você vai ler por aqui provavelmente você já teve contato, porém, nunca se atentou a sua importância. Iremos explorar um pouco do que é o protocolo HTTP, quais são seus métodos principais. Além disso, iremos explorar um pouco da teoria por trás da arquitetura cliente e servidor. Exploraremos ainda algumas ferramentas feitas para desenvolvedores dentro dos navegadores e acompanhar requisições.
Esse artigo faz parte de uma sequência de artigos que eu publiquei sobre esse assunto. Clique aqui para ver mais sobre isso.
O que é o protocolo HTTP?
Dentro do contexto de introdução a Programação web, não poderiamos falar desse protocolo. O HTTP é uma sigla de HyperText Transfer Protocol que em português significa “Protocolo de Transferência de Hipertexto”. É um protocolo de comunicação entre sistemas de informação que permite a transferência de dados entre redes de computadores, principalmente na World Wide Web (Internet).
O HTTP é o protocolo utilizado para transferência de páginas HTML do computador para a Internet. Por isso, os endereços dos websites (URL) utilizam no início a expressão “http://”, definindo o protocolo usado. Esta informação é necessária para estabelecer a comunicação entre a URL e o servidor Web que armazena os dados, enviando então a página HTML solicitada pelo usuário.
Para que a transferência de dados na Internet seja realizada, o protocolo HTTP necessita estar agregado a outros dois protocolos de rede: TCP (Transmission Control Protocol) e IP (Internet Protocol). Esses dois últimos protocolos formam o modelo TCP/IP, necessário para a conexão entre computadores clientes-servidores.
Métodos HTTP mais utilizados
O protocolo disponibiliza aos usuários alguns métodos que dão uma “dica” ao servidor qual a intenção do usuário com aquela requisição. Na versão 1.1 do HTTP existem 9 verbos disponíveis para serem utilizados. É importante que o desenvolvedor compreenda qual a semântica da utilização destes métodos para que sejam utilizados corretamente.
- GET – Essa é a requisição mais comum quando estamos programando para web. É com o método GET que nós solicitamos um recurso ao servidor. Você pode solicitar diversos tipos de recursos, pode ser um arquivo html ou então formatos como XML ou JSON.
- POST – O método POST também é uma figurinha carimbada dentro do mundo da programação Web. Ele é usado quando queremos “postar” ou “criar” um conteúdo em nosso servidor. É importante lembrar que esses dados os dados vão no corpo da requisição e não na URI.
- PUT – Esse verbo não é muito comum, porém, sua função é guardar um recurso na URI ou atualizá-lo.
- DELETE – Esse é bem fácil e intuitivo, ele simplesmente solicita a deleção de um recurso.
Os métodos apresentados acima são considerados “comuns” dentro do protocolo, no entanto, o HTTP possui vários outros métodos mais “obscuros” que podem ser utilizados normalmente. Por exemplo:
- CONNECT – é usado para converter uma requisição de conexão para um túnel TCP/IP transparente, em geral ela é usada para facilitar a comunicação criptografada com SSL (HTTPS) usando um proxy HTTP não criptografado.
- HEAD – Retorna somente os cabeçalhos de uma resposta.
Você quer saber mais sobre outros métodos? veja esse artigo com uma explicação mais detalhada.
A arquitetura cliente-servidor
A arquitetura cliente-servidor pode parecer complexa, mas acredite, não é. Essa arquitetura descreve algo que você utiliza diariamente e basicamente define como uma aplicação web deve se comportar. Quando falamos “servidor” queremos nos referir a uma máquina que fornece uma função ou serviço a um ou mais clientes. Ao mesmo tempo, os clientes são aqueles que consomem serviços do servidor. Pense nisso como uma troca de e-mails, você manda dados para um servidor que automaticamente te avisa que seu e-mail foi enviado, a seguir, o destinatário também é avisado que ele possui uma nova mensagem.
Essa arquitetura “cliente-servidor” tornou-se uma das ideias centrais de computação de rede. Muitos aplicativos de negócios, escritos hoje, utilizam essa arquitetura e o termo também tem sido utilizado para distinguir a computação distribuída por computadores dispersos (essa é uma outra história). Cada instância de software do cliente pode enviar requisições a vários servidores. Por sua vez, os servidores podem aceitar esses pedidos, processá-los e retornar as informações solicitadas para o cliente. Embora este conceito possa ser aplicado por uma variedade de razões e para diversos tipos de aplicações, a arquitetura permanece fundamentalmente a mesma.
Tipos ou Modelos de Client/Server
Após vários modelos estudados de cliente-servidor caracterizou-se chamar tecnicamente de arquitetura multicamada, inspirado nas camadas no Modelo OSI, o processo de dividir a arquitetura de cliente-servidor em várias camadas lógicas facilitando o processo de programação distribuída, existe desde o modelo mais simples de duas camadas, e o mais utilizado atualmente que é o modelo de três camadas que é paralelo ao modelo de arquitetura de software denominado MVC (Model-view-controller). [1]
Características do Cliente
Agora vamos entender como o cliente faz suas requisições, para isso vamos estipular um “passo-a-passo” que toda requisição segue:
- Inicia pedidos para servidores – esse pedido geralmente é um simples digitar de uma URI no navegador;
- Espera por respostas – o cliente (navegador) fica carregando as informações por meio da sua internet;
- Recebe respostas – o servidor ao receber o pedido manda as respostas para o cliente que as recebe;
É importante notar que o cliente geralmente possui um número máximo de conexões simultâneas e geralmente esse número tende a ser reduzido. Normalmente, o cliente interage diretamente com os servidores através de seu software aplicação especifico, que lhe possibilita a comunicação com o servidor (o famoso navegador).
Características do Servidor
Ao mesmo tempo temos também as características de um servidor:
- Espera pedidos – O servidor fica 24 horas esperando o pedido de um cliente;
- Atende os pedidos – quando um pedido chega, o servidor se ocupa em responder aos clientes com os dados solicitados;
- Busca recursos – os servidores são máquinas inteligentes e podem também se conectar com outros servidores para atender uma solicitação específica.
- Envia os recursos – o servidor através da rede depois de processar o pedido, envia os dados de resposta ao cliente.
Assim como toda arquitetura, o cliente-servidor possui vantagens e desvantagens. Veja algumas delas:
Vantagem
- Na maioria dos casos, a arquitetura cliente-servidor permite que os papéis e responsabilidades de um sistema de computação possam ser distribuídos entre vários computadores independentes que são conhecidos por si só através de uma rede. Isso cria uma vantagem adicional para essa arquitetura: maior facilidade de manutenção. Por exemplo, é possível substituir, reparar, atualizar ou mesmo realocar um servidor de seus clientes, enquanto continuam a ser a consciência e não afetado por essa mudança [1].
- Todos os dados são armazenados nos servidores, que geralmente possuem controles de segurança muito maiores do que a maioria dos clientes. Os servidores podem controlar melhor o acesso a recursos, para garantir que apenas os clientes com credenciais válidas possam aceder e alterar os dados [1];
- Como o armazenamento de dados é centralizado, as atualizações dos dados são muito mais fáceis de administrar em comparação com o paradigma P2P. Em uma arquitetura P2P, atualizações de dados podem precisar ser distribuídas e aplicadas a cada nó na rede, o que consome tempo e é passível de erro, já que pode haver milhares ou mesmo milhões de nós[1];
- Muitas tecnologias avançadas de cliente-servidor estão disponíveis e foram projetadas para garantir a segurança, facilidade de interface do usuário e facilidade de uso [1];
- Funciona com vários clientes diferentes de capacidades diferentes [1].
Desvantagens
- Clientes podem solicitar serviços, mas não podem oferecê-los para outros clientes, sobrecarregando o servidor, pois quanto mais clientes, mais informações que irão demandar mais banda[1].
- Um servidor poderá ficar sobrecarregado caso receba mais solicitações simultâneas dos clientes do que pode suportar[1];
- Este modelo não possui a robustez de uma rede baseada em P2P. Na arquitetura cliente-servidor, se um servidor crítico falha, os pedidos dos clientes não poderão ser cumpridos. Já nas redes P2P, os recursos são normalmente distribuídos entre vários nós. Mesmo se uma ou mais máquinas falharem no momento de download de um arquivo, por exemplo, as demais ainda terão os dados necessários para completar a referida operação[1].
O que são cabeçalhos, cookies e como visualiza-los
Para identificar uma requisição feita os navegadores criam uma estrutura de texto chamada de “cabeçalho”. O cabeçalho é enviado em todas as requisições para o servidor para que seja possível receber uma resposta adequada. Veja um exemplo:
Request URL: https://www.globo.com/
Request Method: GET
Status Code: 200
Remote Address: 186.192.81.5:443
Referrer Policy: no-referrer-when-downgradeO que é um Cookie?
Basicamente, um Cookie é um arquivo de texto muito simples, cuja composição depende diretamente do conteúdo do endereço Web visitado. Por exemplo, a maioria do sites armazenam informações básica, como endereços IP e preferências sobre idiomas, cores, etc. Contudo, em portais como o Gmail e o Hotmail, nomes de usuários e senhas de email também fazem parte dos Cookies.
Como funciona o Cookie?
Quando você visita um site pela primeira vez, este envia um Cookie como resposta para o seu navegador, contendo as suas preferências, em formato de texto. Este pequeno arquivo ficará armazenado em seu computador até que perca sua validade.
Enquanto o cookie estiver salvo em seu PC, toda vez que você digitar o endereço do site, o seu navegador irá enviar este arquivo para o site que você está conectado. Desta maneira, as suas configurações serão aplicadas de maneira automática.
Como visualizar estas informações no seu navegador?
Na maioria dos navegadores você encontra uma opção avançada de navegação nos códigos fonte de uma página. Se você utiliza o Google chrome, por exemplo, apenas apertando a tecla F12, uma janela adicional será aberta:
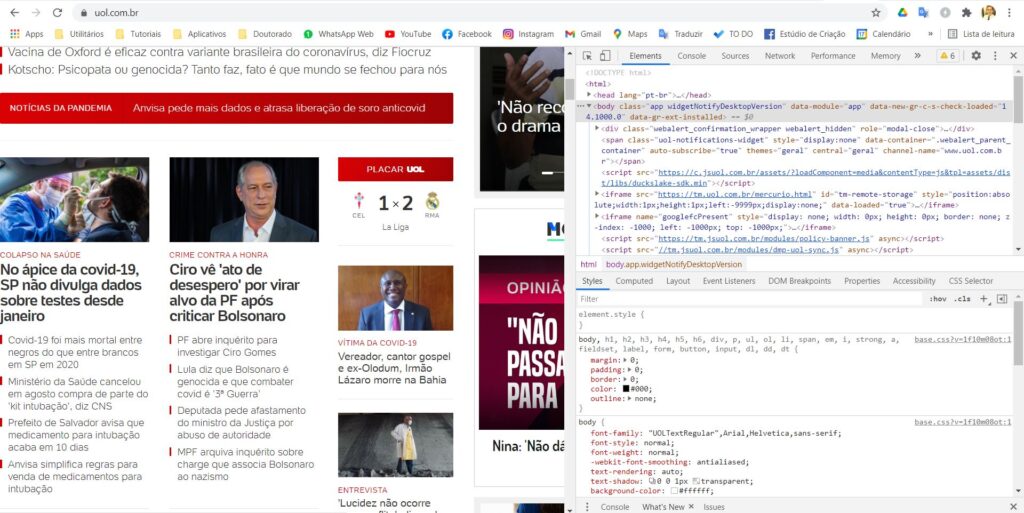
Observe que nessa janela você encontra várias abas. Em cada uma delas existem ferramentas muito legais para visualizar algumas características da página e da requisição feita.
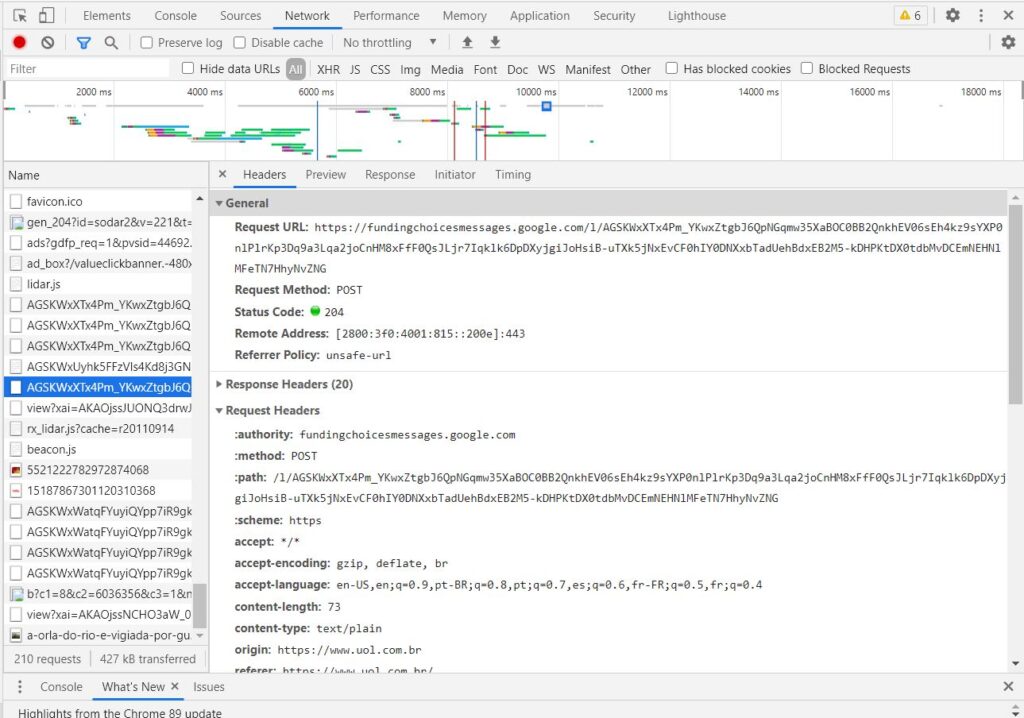
Você pode por exemplo clicar na aba NETWORK você poderá acompanhar todo trafego dentro do seu navegador. Ao clicar em uma das requisições você encontra os cabeçalhos e outras informações interessantes sobre as requisições.
Referências
[1] https://pt.wikipedia.org/wiki/Modelo_cliente%E2%80%93servidor


