
Nessa aula de PLN você vai compreender como podemos usar REGEX para realizar o pré-processamento de textos escritos em linguagem natural usando o python para manipular os textos e processar as expressões.
Antes de mais nada você precisa entender que o REGEX não é uma funcionalidade exclusiva do python, na verdade essas expressões estão presentes em vários sistemas operacionais e a maioria das linguagens já implementam processadores de REGEX.
Nosso objetivo nesse post não é ensinar como você deve escrever expressões regulares, até porquê isso seria um assunto muito extenso, mas aqui vamos dar dicas de como essas expressões podem ser usadas para remover pequenos ruídos que podem resultar em problemas em seus scripts.
Você gosta de aprender sobre processamento de linguagem natural? Veja nosso curso gratuito.
Como utilizar o python para pré processar texto?
O primeiro passo para realizar o pré-processamento de texto é definir seu objetivo. É importante entender que o pré-processamento é realizado para reduzir o ruído do modelo que será aplicado para análise dos dados. Sendo assim, nesse post vamos mostrar um exemplo da remoção de vários caracteres indesejados em um texto.
O primeiro passo é importar o módulo para REGEX (expressões regulares):
import re
Faça a leitura de algum texto para pré-processar (arquivo ou então strings hardcoded):
# você pode usar strings hardcoded
content = "some text 1 some text 2 some text 3 "
# ou então usar arquivos com texto
file = open('sampleText', 'rb')
content = file.read()
content = str(content)
A partir deste ponto você poderá localizar o texto desejado por meio de um padrão e substituir por um espaço ou uma string vazia:
#remove any digit that you do not want in text
removeSharp = re.sub('[0-9]+', ' ', content)
removeSharp
output:
some text some text some text
É claro que as expressões regulares podem buscar padrões bastante complexos e podem se tornar difíceis de entender. Mas calma, existem tutoriais incríveis que ensinam como você poderia extrair ruídos de texto.
Quer ver um tutorial top sobre isso? veja aqui.
Mas se você já conhece um pouco de REGEX e quer testar seus códigos para entender se eles estão filtrando todas as ocorrências eu recomendo utilizar o site Regex101.
Um tutorial rápido sobre o REGEX101
Ao entrar no site, você se depara com a interface principal do REGEX101:
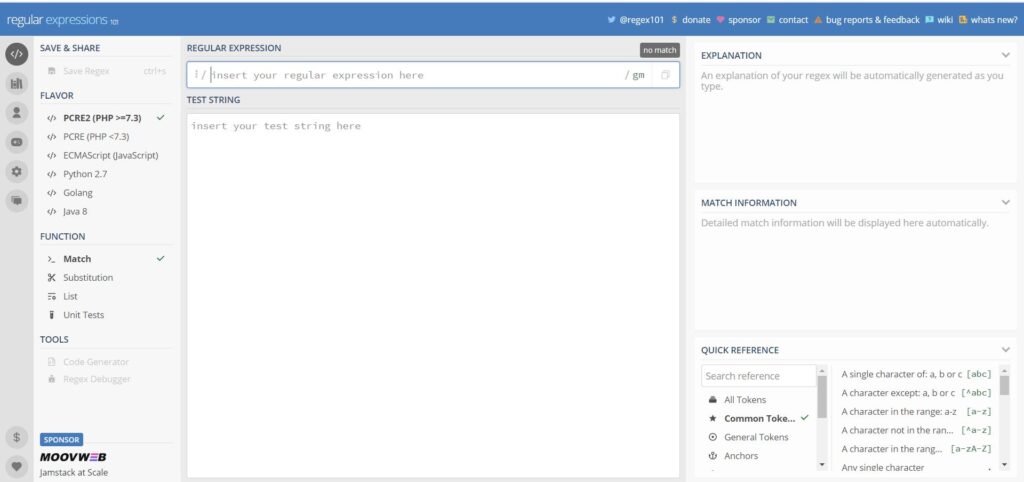
Repare que existem dois campos em destaque, uma área mais fina acima com a seguinte instrução: “insert your regular expression here”. Nesse campo você deverá escrever uma expressão que será “executada” sobre o campo de baixo (“insert your text string here”).
Vamos ver um exemplo prático:
Considere o início desse texto publicado na wikipedia sobre Xadrez.
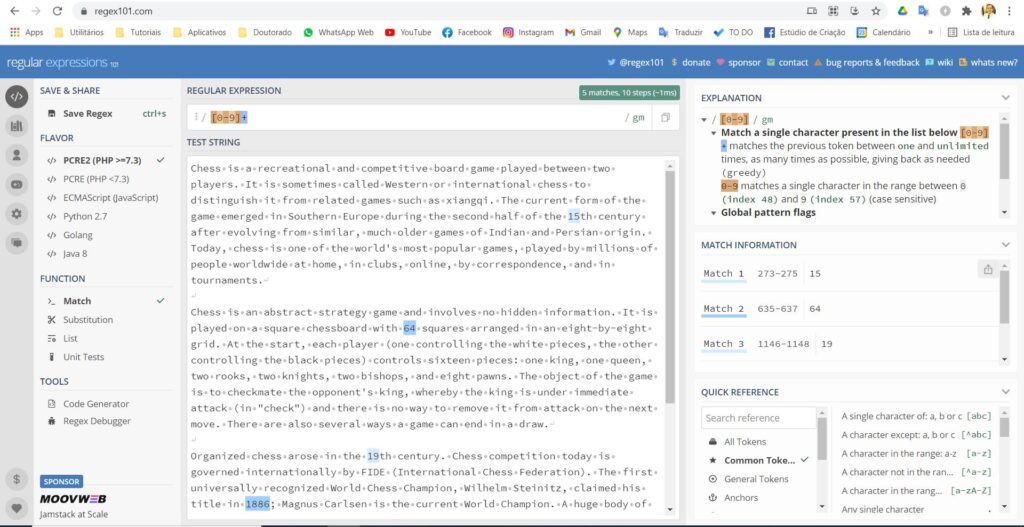
Nosso objetivo é extrair todos os números que estão presentes nesse artigo, portanto escrevemos a seguinte expressão regular:
[0-9]+
Essa expressão significa que o processador irá procurar números de 0 até 9, além disso, mesmo que exista mais de 1 numero é possível realizar essa captura, para isso usamos o sinal de +.
Conclusão
O pré-processamento usando REGEX em tarefas de PLN é um processo muito particular de cada projeto, cabe a você pesquisador decidir se você pode usar essa ferramenta e como isso pode ser um benefício.



