Nessa aula aprenderemos o que é a regressão linear simples e como ela realiza a previsão de um valor, além disso, veremos um exemplo simples de como implementar utilizando o Scikit-Learn.
O que é regressão linear?
No contexto de estatística ou econometria, a regressão linear é definida como uma equação que visa estimar a condicional (valor esperado) de uma variável y, com base nos dados e valores de algumas outras variáveis x. A regressão, em geral, busca tratar de um valor que não se é possível consegue estimar inicialmente. Uma regressão só é chamada “linear” quando se considera que a relação da resposta às variáveis é tratada como uma função linear (Ax+b). Aqueles modelos de regressão que não podem ser traduzidos em uma função linear dos parâmetros são denominados não-lineares. Esse tipo de regressão é uma das primeiras formas de análise regressiva a ser estudada, e também é usada extensamente em aplicações práticas. Isso só acontece porque modelos que dependem de uma forma linear de seus parâmetros desconhecidos, são mais facilmente ajustados que os modelos não-lineares, além disso, as propriedades estatísticas dos estimadores resultantes são fáceis de determinar.
Implementando um exemplo em Python
O primeiro passo para implementar a regressão linear é entender que esse tipo de aprendizado vai retornar um valor aproximado de uma variável que segue uma linearidade. Por exemplo, preços de planos de saúde conforme idade.
Para o nosso exemplo utilizaremos a base de dados de preços de casas e consideraremos dessa base apenas o preço delas e o tamanho. Faça o download do dataset e também do código aqui.
O primeiro passo é importar as bibliotecas necessárias:
import pandas as pd
O segundo passo é pegar os dados na base de dados e dividi-los em base de teste e base de treinamento.
base = pd.read_csv('house-prices.csv')
# pega os valores das casas e a metragem
X = base.iloc[:, 5:6].values
y = base.iloc[:, 2].values
# divide o dataset em test e treinamento
from sklearn.model_selection import train_test_split
X_treinamento, X_teste, y_treinamento, y_teste = train_test_split(X, y, test_size = 0.3, random_state = 0)
A seguir, realizamos o treinamento:
from sklearn.linear_model import LinearRegression regressor = LinearRegression() regressor.fit(X_treinamento, y_treinamento) score = regressor.score(X_treinamento, y_treinamento)
A partir desse ponto podemos utilizar nosso objeto para criar uma visualização:
import matplotlib.pyplot as plt
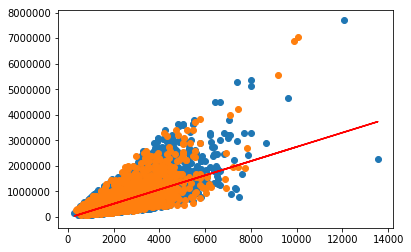
#Coloca os pontos em um gráfico de scatter plt.scatter(X_treinamento, y_treinamento)
# cria a reta plt.plot(X_treinamento, regressor.predict(X_treinamento), color = 'red')
# realiza previsões previsoes = regressor.predict(X_teste) resultado = abs(y_teste - previsoes) resultado.mean() from sklearn.metrics import mean_absolute_error, mean_squared_error mae = mean_absolute_error(y_teste, previsoes) mse = mean_squared_error(y_teste, previsoes) plt.scatter(X_teste, y_teste) plt.plot(X_teste, regressor.predict(X_teste), color = 'red') regressor.score(X_teste, y_teste) plt.show()