
Nesse post vou ensinar passo a passo como você pode usar o Python para automatizar uma tarefa bastante chata que é extrair dados de um boleto (em PDF). Com essa técnica você pode, por exemplo, juntar um conjunto de documentos em PDF fazer a leitura de todos eles usando o Python e exportar todos esses dados em CSV. Algo que antes era aparentemente impossivel de se automatizar, hoje pode ser codificado e ajudar no seu cotidiano.
Ferramentas prontas para extração de dados de boletos (invoice)
Antes de mais nada, precisamos dizer que assim como a mineração de dados da web a extração de informações de documentos (seja hipertexto, word, pdf) é uma tarefa bastante conhecida e já existem diversas ferramentas que podem ajudar. Com a evolução das tecnologias, cada vez mais as pessoas comuns buscam automatizar tarefas que antes precisavam de um esforço manual grande e isso acabou se tornando até mesmo um segmento de mercado. Assim, existem desenvolvedores que se especializaram em criar aplicações exclusivamente para isso e comercializam esses softwares.
Algumas organizações estão investindo cada vez mais dinheiro em alinhar as novas técnicas de inteligência artificial com a extração de informações. Quer ver um exemplo? O site nanonets promete usar Deep Learning e OCR (leitura de dados em imagens) para extrair informações de “boletos”. Além do nanonets, existem vários outros que vendem o mesmo serviço:
Muitos desses serviços são baseados em API’s REST onde você poderá enviar um arquivo e ele retorna as informações do boleto em JSON, prontinho para ser consumido pela sua aplicação. Sabe qual é a grande desvantagem de todos esses serviços? A maioria deles é pago.
Para exemplificar como esse trabalho é importante e o quanto ele pode ser difícil de codificar, podemos citar o caso das empresas que transformaram essa tarefa em um trabalho remunerado. É isso mesmo, algumas empresas contratam pessoas para fazer a digitação de dados de notas fiscais pagando um salário e comissão por produtividade.
Como é possível extrair esses dados? deve ser muito complicado!
Realmente, não vou negar que as técnicas aplicadas pelos softwares que mencionei anteriormente são bastante complexas. Aprender o que é uma rede neural, deep learning, OCR, entre outros, pode ser tão difícil que até você conseguir aprender tudo isso, você já poderia ter digitado manualmente milhares de notas.
Mas não desista! existem soluções, talvez não tão incríveis quanto as soluções propostas por essas empresas, mas que ainda são funcionais para sua necessidade.
Para mostrar uma dessas soluções vou dividir esse tutorial em 4 partes:
- Configuração do ambiente
- Criando os templates
- Executando o código e exportando os resultados
Configuração do ambiente
O primeiro passo para fazer isso tudo funcionar é ter seu ambiente muito bem configurado. Existem milhares de formas de fazer isso e você pode preferir criar um ambiente do seu jeito (instalando apenas aquilo que você acha que é necessário). Para ajudar nessa tarefa vou mostrar aqui como eu configurei o meu ambiente (ao meu ver a forma mais fácil).
A primeira coisa que precisamos instalar é o nosso amado Anaconda. Eu já expliquei com mais detalhes como fazer isso, então se você não tem ele instalado, clique aqui e siga o tutorial.
A seguir, eu recomendo que você crie um novo ambiente (separado do base) por alguns motivos:
- Esse ambiente permite que você escolha qual versão do Python você quer trabalhar (isso é necessário para usar as bibliotecas que vamos precisar)
- Você possui mais controle sobre quais ferramentas você baixou naquele ambiente e fica mais fácil para replicar posteriormente.
Para esse tutorial vou criar um ambiente novo usando o Python 3.6:
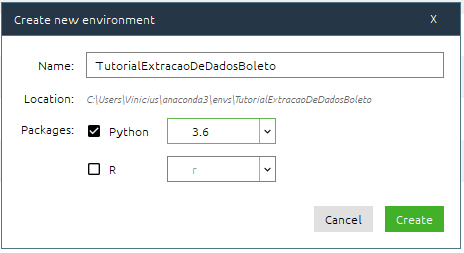
Depois disso você precisa acessar o anaconda navigator e o prompt de comando do anaconda, em seguida digite:
pip install invoice2dataEstamos prontos para iniciar nossa solução!
Como definir um template para o invoice2data
Se você já pagou boletos em sua vida, você pode ter percebido que cada boleto pode ser bem diferente um do outro, isso depende muito de como esse boleto foi gerado. O método mais comum para gerar boletos é utilizando uma imagem de fundo com elementos gráficos que indicam a identidade visual da empresa emissora e uma tabela é colocada por cima desse “fundo”. Por exemplo, considere a empresa “escuro” de telefonia celular que emitiu o seguinte boleto:

Quando esse “fundo” passa pelo sistema e recebe os dados, fica mais ou menos assim:

Talvez pela foto fique difícil perceber, mas é possível ver o que faz parte do fundo e o que faz parte das tabelas por algumas distorções na qualidade (pixelização) das imagens quando comparados com o texto.
Mas por quê estou explicando tudo isso?
Bom, se vamos extrair dados de um boleto esses dados precisam estar disponíveis de alguma forma em nosso PDF. No entanto, muitas vezes o PDF inteiro ou então algumas partes do PDF não passam de uma imagem, isso prejudica bastante a extração de dados.
Para solucionar esse problema seria necessário um software chamado OCR (Optical character recognition), no entanto, nesse post não vou tratar sobre isso.
Agora para extrair os dados eu preciso definir um “modelo”, esse modelo é simplesmente uma forma de você dizer ao software quais são os dados que você quer extrair, para isso vamos usar expressões regulares e um arquivo do tipo YML.
Se você não sabe nada sobre Regex veja um artigo aqui que mostra o básico sobre regex. Além disso um excelente website para você treinar é o regex 101.
Passo 1: entenda o que é o YAML
O YAML é uma estrutura muito parecida com o JSON que permite criar uma lógica chave:valor que pode ser posteriormente lida por algum software. Por exemplo, se quero construir um arquivo YML com os meus dados seriam mais ou menos assim:
tipo: "pessoa"
características:
nome: "vinicius"
cpf: "132549135-00"
telefone: "351395-1235"
profissão: "desevolvedor"Passo 2: entenda quais características são essenciais para criar um template
Para usar o invoice2data precisamos criar um template com todos os parâmetros que a biblioteca considera indispensável. Ao verificar a documentação vemos alguns exemplos de templates funcionais como esse:
issuer: Amazon Web Services, Inc.
keywords:
- Amazon Web Services
exclude_keywords:
- San Jose
fields:
amount: TOTAL AMOUNT DUE ON.*\$(\d+\.\d+)
amount_untaxed: TOTAL AMOUNT DUE ON.*\$(\d+\.\d+)
date: Invoice Date:\s+([a-zA-Z]+ \d+ , \d+)
invoice_number: Invoice Number:\s+(\d+)
partner_name: (Amazon Web Services, Inc\.)
options:
remove_whitespace: false
currency: HKD
date_formats:
- '%d/%m/%Y'
lines:
start: Detail
end: \* May include estimated US sales tax
first_line: ^ (?P<description>\w+.*)\$(?P<price_unit>\d+\.\d+)
line: (.*)\$(\d+\.\d+)
last_line: VAT \*\*A verdade é que nem todas essas linhas são obrigatórias, no meu caso eu queria apenas:
- Nome da empresa
- valor da conta
- data de vencimento
- número do boleto
Então eu montei o seguinte YAML:
issuer: Telefonica Brasil S.A.
keywords:
- Vivo
- Telefonica Brasil S.A.
fields:
amount: AR\s+([0-9.]+\d+)
date:
- ncia\W\s+(\d+\/\d+)
invoice_number: da Conta\W\s+(\d+)
options:
currency: BRL
date_formats:
- '%d/%m/%Y'
decimal_separator: ","O campo Issuer é obrigatório e corresponde a uma simples string com o nome do emissor do boleto, no entanto, as keywords apresentadas logo a seguir é um regex que será localizado dentro do PDF, portanto, se você inserir um regex inválido ele te mostrará um erro assim:

é, eu sei, esse erro não é muito intuitivo, mas…
A seguir você encontra o campo amount, date e invoice number. Esses campos seguem a mesma lógica, são um regex que irá localizar exatamente onde o valor está no boleto. Quando eu precisei criar esses templates eu otimizei esse processo da seguinte forma:
Primeiro, eu abri meu PDF do meu boleto e pressionei CTRL + A:

Copíei todo o conteúdo (CTRL + C) e depois colei no regex 101:
Agora eu posso criar e testar meu regex! Por exemplo, se eu quiser selecionar o total a pagar eu faria algo assim:
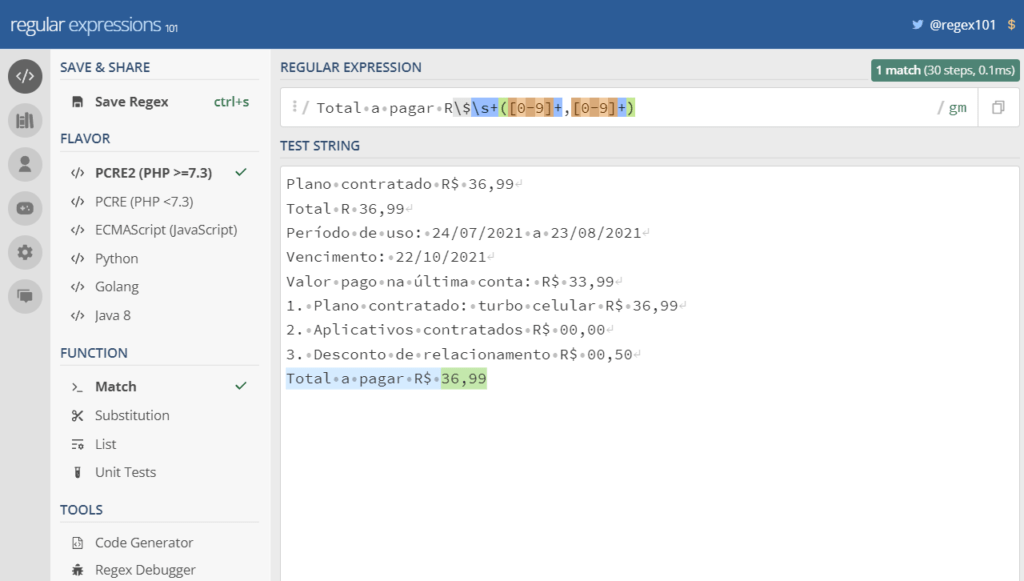
Por fim, temos algumas opções que são a moeda corrente (BRL – Real) e também formatos de data e o separador decimal usado (ponto ou vírgula).
Executando e exportando os resultados
Depois de definir seu modelo, podemos fazer a extração dos dados, para isso vamos importar as bibliotecas necessárias:
from invoice2data import extract_data
from invoice2data.extract.loader import read_templatesDepois podemos informar para a biblioteca onde fica sua pasta de templates (podemos criar vários deles) e colocar os resultados dentro de uma lista:
templates = read_templates("Template/")
result = []
for i in range(1,4):
result.append(extract_data("Invoice/nome_conta" + str(i) + ".pdf", templates=templates))
Estou utilizando um “for” para exemplificar a extração de dados de várias contas de uma só vez. Por fim, você pode escrever um novo arquivo CSV ou do Excel para exportar esses dados:
csv_file = "invoices.csv"
csv_columns = ['amount','currency','date','desc','invoice_number','issuer']
with open(csv_file, 'w') as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=csv_columns)
writer.writeheader()
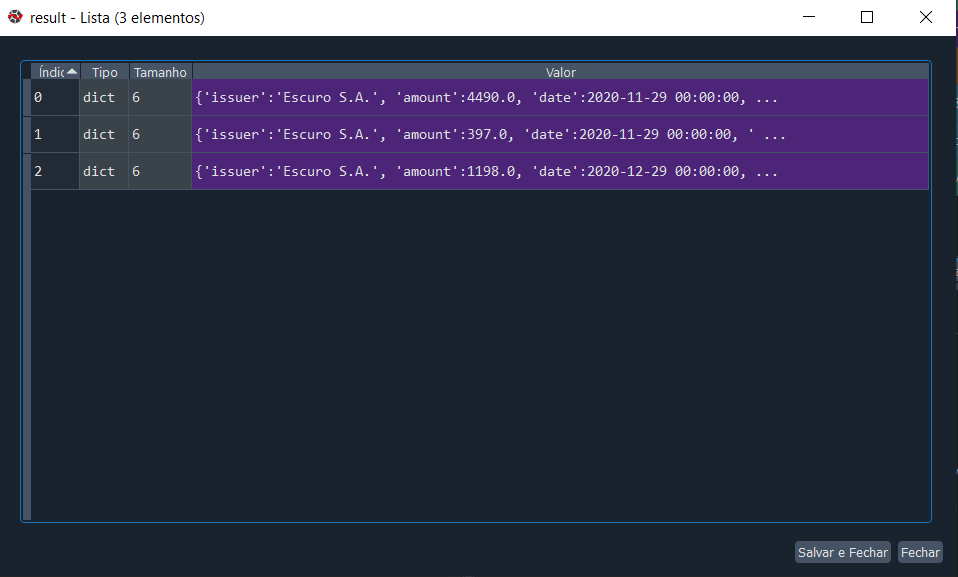
for data in result:
writer.writerow(data)Quando rodamos nosso programa, você verá a variável “data” preenchida assim:
Problemas de usar o invoice2data
Essa ferramenta é bastante poderosa e pode economizar muito tempo do desenvolvedor python que quer automatizar esse processo de mineração de dados, no entanto, na minha opinião existem algumas limitações importantes, são elas:
- Definir um template abrangente o bastante pode ser muito problemático devido aos muitos formatos que um boleto pode ter;
- Trabalhar com regex pode ser difícil para iniciantes;
- A biblioteca não possui erros muito amigáveis e algumas vezes é difícil entender o por quê seu programa não roda;
Se você quiser acessar o código fonte do meu exemplo visite nosso Github:



